

Auswertung von Ausdrücken



Next:Input / OutputUp:Grundlegende SprachelementePrevious:Beispiel: Newton-Approximation
Auswertung von Ausdrücken
= Reduktion auf die einfachste äquivalente Form als Antwort
dazu: verwende "`eingebaute"' Semantik für primitive Operationen und die vom Programmierer gelieferten Definitionen, nämlich: ersetze linke Seite einer definierenden Gleichung durch rechte Seite.
- Beispiel:
-
gegeben:
pi = 3.14
area x = pi * x * x
dann:
area (9+1)
=> area 10 Semantik "+"
=> pi * 10 * 10 Definition "area"
=> 3.14 * 10 * 10 Definition "pi"
=> 31.4 * 10 Semantik "*"
=> 314 Semantik "*"
(dabei angenommen, was stimmt, daß Folgen von ``*'' unter Assoziation nach links ausgewertet werden)
Das ist nicht die einzig mögliche Reduktionsfolge!
- Alternative:
-
area (9+1)
=> pi * (9+1) * (9+1) Definition "area"
=> 3.14 * (9+1) * (9+1) Definition "pi"
=> 3.14 * 10 * (9+1) "+"
=> 31.4 * (9+1) "*"
=> 31.4 * 10 "+"
=> 314 "*"
Im ersten Beispiel wird zuerst der innere Teilausdruck ``(9+1)'' ausgewertet, während im zweiten Beispiel die Auswertung von außen nach innen geschieht; man spricht (bei konsequenter Anwendung der Vorgehensweisen) von "`innermost"' und "`outermost"' Strategie.
Haskell verwendet "`outermost"' mit dem wichtigen Zusatz, daß Mehrfachvorkommen desselben Teilausdrucks nur einmal ausgewertet werden.
- also im Beispiel:
-
area (9+1)
=> pi * (9+1) * ( )
>---^
=> 3.14 * (9+1) * ( )
>---^
=> 3.14 * 10 * 10
=> ...
Outermost-Reduktion mit dieser Optimierung heißt auch "`lazy evaluation"': Ein Teilausdruck wird erst ausgewertet, wenn es wirklich nicht mehr anders geht, und dann auch nur einmal.
 möglich, daß Teilausdruck gar nicht ausgewertet,
möglich, daß Teilausdruck gar nicht ausgewertet,
möglich, daß das Scheitern einer Berechnung vermieden wird!
- Beispiel:
-
definiere: first_of_two x y = x dann: first_of_two 1 (1 `div` 0) => 1 - outermost!
Bei innermost gäbe es hier einen Laufzeitfehler!
ähnlich: nicht-terminierende Teil-Berechnung.
- Welche Strategie ist besser?
-
Keine eindeutige Antwort; verschiedene Programmiersprachen verhalten sich verschieden:
innermost (auch: "`eager evaluation"'):
Lisp-Dialekte, ML (funktionale Sprachen) imperative Sprachen!
mit kleinen Ausnahmen, z.B.:
if ... then ... else ...
... and then ...
... or else ...
- Theorie sagt:
-
Wenn innermost ein Ergebnis liefert, dann liefert outermost dasselbe Ergebnis - aber es kann sein (siehe oben), daß nur outermost ein Ergebnis liefert!
- outermost Vorteile:
Erlaubt gewisse Programmstrukturen, die mit unendlichen Datenstrukturen ( nicht terminierende Berechnungen) arbeiten.
- outermost Nachteile:
Implementierung schwieriger und aufwendiger
- outermost Vorteile:
- noch ein damit zusammenhängender Begriff:
-
weil Auswertung eines Ausdrucks scheitern kann, ist es bequem (für theoretische Überlegungen), alle Wertebereiche durch einen besonderen Wert zu ergänzen:
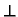
= "`undefiniert"' = "`bottom"' steht für Laufzeitfehler oder Nichtterminierung dann:
Funktion f heißt strikt gdw. f
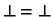 .
.arithmetische Operationen sind immer strikt -- klar, 3 mal undefiniert is undefiniert --, aber bei lazy evaluation gibt es auch nicht strikte Funktionen:
- Beispiel:
- konstante Funktionen wie z.B.:
three x = 3
dann:
three (1/0)
=> 3 - outermost!
all_ints_from :: Int -> [Int]
all_ints_from x = x : all_ints_from(x+1)
first_even :: [Int] -> Int
first_even x:xs
| even x = x
| otherwise = first_even xs
Next:Input / OutputUp:Grundlegende SprachelementePrevious:Beispiel: Newton-Approximation Ronald Blaschke
1998-04-19