

Beispiel: Text-Verarbeitung
Beispiel: Text-Verarbeitung
Texte sind zunächst einach Zeichnreihen:
type Text = String
die aber zur Verwaltung / Verarbeitung verschiedenen Sichtweisen unterworfen werden, z.B.:
type Line = String - Zeile, ohne '\n'
type Word = String - Wort, ohne ' ', '\n'
type Para = [Line] - Absatz = Zeilenfolge
Wir betrachten die Umwandlung:
asLines:: Text->[Line]
zu deren Definition einige Entscheidungen nötig sind (natürlich sind solche Spezifikationen nicht zwingend):
- 1.
- Text ohne '
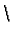 n' gibt Zeile:
n' gibt Zeile: asLines "Das ist ein Text" = ["Das ist ein Text"]
dann aber auch:
asLines "" = [""] = [[]]
d.h. leerer Text gibt eine Leerzeile.
- 2.
-
' n' ist Trennzeichen (nicht: Anfangs-/Endezeichen):
asLines "Das ist \n ein Text" = ["Das ist", "ein Text"]
asLines "Das ist ein Text\n" = ["Das ist ein Text", []]
d.h. #Zeilen = #newline + 1
- 3.
- Es gibt keinen Umbruch gemäß einer maximalen Zeilenlänge und keine Normalisierung durch Weglassen oder Einfügen von Leerzeichen:
asLines "Das ist ein Text " = ["Das ist ein Text "]
Lösungsansatz:
wir betrachten versuchsweise die Definition
asLines = foldr op start
und überlegen uns geeignete Definitionen für start und op.
man erinnere sich:
-
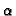
- foldr :: (a->b->b) -> b -> [a] -> b
-
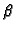
- foldr op start [] = start
-
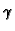
- foldr op start (x:xs) = x `op` (foldr op start xs)
wir schließen:
-
asLines :: Text->[Line], also foldr start op :: Text->[Line]
also wegen
:b = [Line]
a = Char
also:
op :: Char -> [Line] -> [Line]
start :: [Line]
-
asLines "" = [[]] (1.)
andererseits wegen
:asLines "" = foldr op start [] = start
d.h.:
start = [[]] - Liste, die nur 1 Leerzeile enthält
-
asLines ¨ein \nText'' = [¨ein", ¨Text"] (1., 2.)
andererseits wegen
:asLines "ein \nText"
= 'e' `op` (asLines "in \nText")
= 'e' `op` ["in", "Text"]
( wegen 1., 2. )
also:
op c ls = (c:head ls) : (tail ls)
falls c/='\n'
-
asLines ¨\n ein \nText" = [[], ¨ein", ¨Text"] (1., 2.)
andererseits wegen
:asLines "\n ein \nText"
= '\n' `op` (asLines "ein \nText")
= '\n' `op` ["ein", "Text"]
( wegen 1., 2. )
also:
op c ls = [] : ls falls c=='\n'
also insgesamt:
asLines:: Text->[Line]
asLines = foldr break_on_newline [[]]
where break_on_newline:: Char->[Line]->[Line]
break_on_newline c ls
|c == '\n' = []:ls -new group
|otherwise = (c:(head ls)) : (tail ls) -add to group
Die in dieser Definition verwendete Funktion "break_on_newline" ist es wert, verallgemeinert zu werden:
offensichtlich analoge Aufgabe, wenn wir einen Text nach Wörtern gruppieren: dann definiert ' ' die Bruchstelle,
wenn wir eine Folge von Zeilen nach Absätzen gruppieren: dann definiert die Leerzeile [] die Bruchstelle.
 aus der Bruchstellenmarkierung einen Parameter machen und die Funktion gleich für beliebige Listen formulieren.
aus der Bruchstellenmarkierung einen Parameter machen und die Funktion gleich für beliebige Listen formulieren.
---------------allgemeines break_on fuer Listen
-behandelt break-elem als Separator
break_on:: Eq a => a->a->[[a]]->[[a]]
break_on b c ls
|c == b = []:ls -new group
|otherwise = (c:(head ls)) : (tail ls) -add to group
------------------------text as lines
asLines:: Text->[Line]
asLines = foldr (break_on '\n') [[]]
Anwendung z.B. so:
Main> break_on '\n' 'd' [``ef'']
[``def'']
Main> break_on '\n' '\n' [``def'']
[", ``def'']
Main> break_on '\n' '\n' [[]]
[", "]
Main> asLines "
["]
Main> asLines ``abc def''
[``abc def'']
Main> asLines ``\nabc \n\ndef\n''
[", ``abc ``, ", ``def'', "]
jetzt machen wir in derselben Weise:
- aus einer Zeile eine Liste von Wörtern:
Trennzeichen = ' '
- aus einer Liste von Zeilen eine Liste von Paragraphen Absätzen:
Trennzeichen = [] = leere Zeile
------------------------lines as words
-no empty words
asWords:: Line->[Word]
asWords = filter (/= []) . foldr (break_on ' ') [[]]
-------------------line lists as paragraphs
-no empty paragraphs
asParas:: [Line]->[Para]
asParas = filter (/= []) . foldr (break_on []) [[]]
Wesentliche Zutat: Wir filtern jetzt leere Wörter und leere Paragraphen heraus (sind funktionslos in der angestrebten Strukturierung von Texten)
Beispiel (microText ist in einem Skript als der unten gezeigte String vereinbart):
Main> microText
"Stille Nacht, \n heilige Nacht, \n\n alles
schlaeft,\n einsam wacht...\n"
Main> asLines microText
["Stille Nacht, ", " heilige Nacht, ", "", " alles schlaeft,", " einsam wacht...", ""]
Main> asParas (asLines microText)
[["Stille Nacht, ", " heilige Nacht, "], [" alles schlaeft,", " einsam wacht..."]]
Main> map (map asWords) (asParas (asLines microText))
[[["Stille", "Nacht,"], ["heilige", "Nacht,"]], [["alles", "schlaeft,"],
["einsam", "wacht..."]]]
|||- Liste von Paras
||
||-- Liste von Zeilen
|
|-- Liste von Worten
Unsere drei Funktionen lassen sich jtzt zusammensetzen, um die Struktur eines Texts zu analysieren (to parse = zerteilen):
parse:: Text->[[[Word]]]
parse = map(map asWords) . asParas . asLines
also z.B.:
Main> microText
"Stille Nacht, \n heilige Nacht, \n\n alles schlaeft,\n einsam wacht...\n"
Main> parse microText
[[["Stille", "Nacht,"], ["heilige", "Nacht,"]], [["alles", "schlaeft,"],
["einsam", "wacht..."]]]
also:
| <Text> | ::= | [<Para>] |
| <Para> | ::= | [<Line>] |
| <Line> | ::= | [<Word>] |
| <Word> | ::= | <print_char> {<print_char>} |
(diese syntaktischen Variablen sind natürlich nicht identisch mit den Haskell Typen)
jetzt neue Aufgabe:
mache Strukturanalyse wieder rückgängig (d.h. mache das Resultat von parse wieder "`flach"')
dazu: füge alle nötigen Separatoren wieder ein!
Dieses Einfügen formulieren wir gleich allgemein, für beliebige Listen concWith
und wenden diese Operation an mit foldr1 (=kein Startelement!)
----------------allgemeines concWith fuer Listen
concWith:: a->[a]->[a]->[a]
concWith x ys zs = ys ++ [x] ++ zs
------------------------Umkehrfunktionen
-re-insert Separatoren
unLines:: [Line]->Text
unLines = foldr1 (concWith '\n')
unWords:: [Word]->Line
unWords = foldr1 (concWith ' ')
unParas:: [Para]->[Line]
unParas = foldr1 (concWith [])
beachte:
- keine exakten Umkehrfunktionen, da wir überflüssige Separatoren entfernt haben;
- funktioniert wegen foldr1 nicht für leere Listen!
Main> (unLines.asLines) "abc \ndef\n"
"abc \ndef\n"
Main> (asLines.unLines)["abc ", "def", ""]
["abc ", "def", ""]
Main> (unWords.asWords) "abc def "
"abc def"
Main> (asWords.unWords) ["abc", "def"]
["abc", "def"]
Main> (unWords.asWords) ""
"
Program error: foldr1 (concWith ' ') []
Main> (unWords.asWords) " "
"
Program error: foldr1 (concWith ' ') []
damit dann die gewünschte Umkehrung von parse:
unparse:: [[[Word]]]->Text
unparse = unLines . unParas . map(map unWords)
Beispiel:
Main> (unparse.parse) microText
"Stille Nacht,\nheilige Nacht,\n\nalles schlaeft,\neinsam wacht..."
= vereinfachte (nicht redundante) Form des Ausgangstexts
simplify:: Text->Text -entferne redundante Separatoren
simplify = unparse . parse
Beispiel:
Main> simplify microText
"Stille Nacht,\nheilige Nacht,\n\nalles schlaeft,\neinsam wacht..."
Main> putStr (simplify microText)
Stille Nacht,
heilige Nacht,
alles schlaeft,
einsam wacht...
Analyse der Struktur eines Texts durch parse kann als Ausgangspunkt dienen für viele weitere nützliche Arbeiten, z.B.:
- Eigenschaften eines Texts ermitteln,
- Änderungen des Texts vornehmen,
- Druckbild gestalten, ...
Beispiel: Texteigenschaften:
countLines = length . asLines
countWords = length . concat. map asWords . asLines
countParas = length . asParas . asLines
Main> countLines microText
6
Main> countWords microText
8
Main> countParas microText
2
Beispiel: Layout
wir betrachten einige einfache Möglichkeiten, aus einem Text ein gewünschtes Druckbild zu erzeugen;
dabei Einschränkungen:
- benutze Zeilenstruktur, die der Hersteller des Texts vorgegeben hat (also kein Zeilenumbruch, aber auch kein Umbruch größerer Einheiten wie z.B. Seiten)
- und normiere Zeilen lediglich durch Einfügen von Füllmaterial (oder Abschneiden) am rechten Rand!
unser Layout arbeitet mit Textblöcken = Folgen von Zeilen gleicher Länge
und arrangiert diese durch vertikale und horizontale Komposition, z.B.:

Textblöcke sind bei uns einfach Listen von Zeichen, und die fällige Normierung der Länge (Einfügen / Abschneiden rechts) formulieren wir gleich in voller Allgemeinheit für beliebige Listen (weil wir damit dann auch die Höhe von Textblöcken normieren können):
-Textblock = Char-Rechteck, d.h. Folge von gleichlangen Zeilen
type Block = [Line] -type synonym
------------------------Hilfsfunktionen
copy:: Int->a->[a] -Liste mit n-mal elem
copy (n+1) elem = elem : copy n elem
copy _ _ = []
ljustify:: Int->a->[a]->[a] -normiert Liste auf Laenge n
-rechts Abschneiden/Auffuellen
ljustify n filler list
= take n list ++ copy (n - (length list)) filler
Beispiel:
Main> copy 9 'a'
"aaaaaaaaa"
Main> copy 9 "a"
["a", "a", "a", "a", "a", "a", "a", "a", "a"]
Main> copy (-2) "a"
[]
Main> ljustify 10 '*' "abc"
"abc*******"
Main> ljustify 10 0 [1,2,3,4,5]
[1, 2, 3, 4, 5, 0, 0, 0, 0, 0]
Main> ljustify 0 ' ' "abc"
""
Ein Textblock entsteht durch Normierung von Zeilenlänge (=Breite des Blocks) und Zeilenanzahl (=Höhe des Blocks)
--------------line lists as height*width blocks
asBlock:: Int->Int->[Line]->Block
asBlock height width
= ljustify height (copy width ' ') -Hoehe
. map (ljustify width ' ') -Breite
Beispiel:
Main> asBlock 3 10 ["erste Zeile", "zweite Zeile"]
["erste Zeil", "zweite Zei", " "]
Main> asBlock 3 15 ["erste Zeile", "zweite Zeile"]
["erste Zeile ", "zweite Zeile ", " "]
Main> putStr (unLines (asBlock 3 15 ["erste Zeile", "zweite Zeile"]))
erste Zeile
zweite Zeile
Main> putStr (unLines (asBlock 2 10 ["Zeile", "Zeile", "keine Zeile"]))
Zeile
Zeile
Main> ((asBlock 5 30).asLines.simplify) microText
["Stille Nacht, ", "heilige Nacht, ", "
", "alles schlaeft, ", "einsam wacht...
"]
Main> (putStr.unLines.(asBlock 5 30).asLines.simplify) microText
Stille Nacht,
heilige Nacht,
alles schlaeft,
einsam wacht...
Textblöcke (geeigneter Dimension) lassen sich horizontal und vertikal kombinieren:
-----------------Komposition von Textbloecken
combHori, combVerti:: Block->Block->Block
combHori = zipWith (++) -requires equal heights!!!
combVerti = (++) -requires equal widths!!!
Dabei ist zipWith eine higher-order Standardfunktion:
zipWith :: (a->b->c)->[a]->[b]->[c]
zipWith op (x:xs) (y:ys) = x `op` y : zipWith op xs ys
zipWith _ _ _ = [] - eine Liste erschöpft
Es folgt ein Layout-Beispiel für
microText = "Stille Nacht ..." - wie gehabt
und
headline = "Weihnachten in Salzburg"
Layout-Beispiel:
layout1 =
(putStr.unLines)
(combVerti
(asBlock 1 30 [])
(combVerti
(((asBlock 2 30).asLines.simplify) headline)
(((asBlock 6 30).asLines.simplify) microText)))
layout2 =
(putStr.unLines)
(combVerti
(asBlock 1 34 [])
(combVerti
(((asBlock 2 34).asLines.simplify) headline)
(combHori
(((asBlock 3 17).asLines.simplify) microText)
(((asBlock 3 17).(drop 3).asLines.simplify) microText))))
Hugs session for:
/usr/local/lib/hugs/lib/Prelude.hs
text_proc
Main> layout1
Weihnachten in Salzburg
Stille Nacht,
heilige Nacht,
alles schlaeft,
einsam wacht...
Main> layout2
Weihnachten in Salzburg
Stille Nacht, alles schlaeft,
heilige Nacht, einsam wacht...



Next:EffizienzUp:ListenPrevious:Wiederaufnahme der Beispiele 3.2 Ronald Blaschke
1998-04-19