

Complex Interaction
Chapter 5. Complex Interaction
- Table of Contents
- Star Architecture
- Mesh
In this chapter I will deal with multiple servers and/or multiple clients. Understanding the findings of Chapter 4 should lead to little surprises here.
In order to be somewhat comparable to Glade (Ada95/AnnexE implementation) I decided for a thread pool with 512 threads, just as Glade does.
Star Architecture
In a star architecture we have a single server and multiple clients.
Since only 4 Sparc 20's are available in the test environment I decided for the following configuration for this section.
- Server (center of the star)
-
Sparc 20, 128 Megabytes TMS390Z55
- Clients
-
Ultra 1, 256 Megabytes UltraSPARC
Method
Two situations are evaluated: A single object for all clients and one object per client. In the first case an object is created at server startup and all clients request the reference to this object and call it. In the latter case a new object is requested by each client and then called. Note that we synchronize right before entering the call loop and allow concurrent access to the objects. As usual, the time needed to create the objects is not included.
...
long t1 = 0;
long t2 = 0;
if (method.equals("sync_VV")) {
RTT rtt = factory.createRTT();
b.barrier(clients); // wait for others
t1 = System.currentTimeMillis();
for (int i=0; i<loops; i++) {
rtt.sync_VV();
}
t2 = System.currentTimeMillis();
}
...
System.out.println(t2-t1);
|
Figure 5-1. StarClient.java
Results
Two different time values can be identified for this: The completion time and the (accumulated) round trip time. The former is the wall clock time needed to process all calls, the latter is the sum of every client's round trip time.
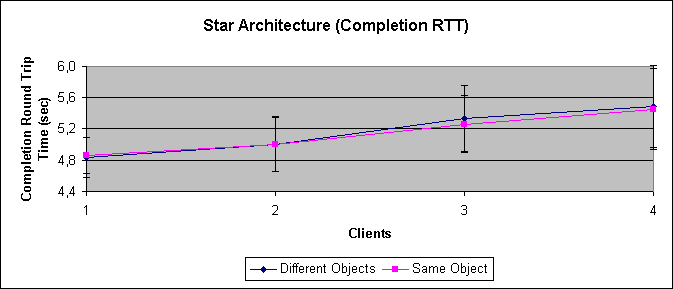
As can be seen in Figure 5-2, the completion round trip time raises. We would have expected a steady or slightly decreasing curve because of interleaving effects. It is likely that there is always one client waiting to be served. But on the other hand, they are fighting for the servers attention, and absolute homogeneity of the clients is not guaranteed (e.g. different system load). In short, some unknown random effects.
Note that we are keeping the number of total calls constant (1000). Thus, for four clients we have 250 calls for each. Since our server is threaded we might get the idea that the calls take only a quarter of the time. However, the dispatcher only accepts one connection at a time and then executes the request in a thread. For these tests the objects contain no code, which nullifies the advantage of the threads.[1][1]
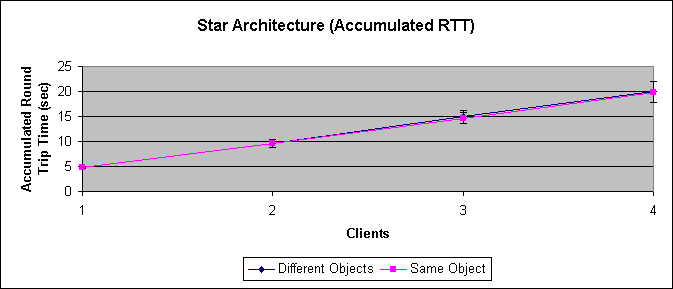
Figure 5-3 shows the (accumulated) round trip time, that is the sum of the round trip times of all clients. As can be seen it is quite linear. For 2 clients each one has its own processing time plus the wait time for the other client, thus doubling the total time, which indicates that the calls are served in a fair manner.
For four clients the completion round trip time is about 5.5ms (Figure 5-2) which, if all 4 are served the same way, multiplies to a total of 22ms. The measured cumulative round trip time is about 20ms. All in all, the calls seem evenly spread.
Using the same object for all clients, or a different one for each client makes no significant difference.
Notes
| [1][1] |
Actually, we add some thread management overhead. |