Mesh
| Projektpraktikum: Performance Analysis Ada95/AnnexE, Java/RMI, CORBA | ||
|---|---|---|
| Prev | Chapter 5. Complex Interaction | Next |
Mesh
For this test of a mesh configuration we have a complete graph: Each node is both server and client and calls all others. A server is used for synchronization and to distribute the object references.
Again, since the test environment only has 4 Sparc 20's I decided for the following configuration.
- Server (synchronization, object references)
-
Sparc 20, 128 Megabytes TMS390Z55
- Nodes
-
Ultra 1, 256 Megabytes UltraSPARC
Method
First of all, we have to run the server in a separate thread since we use the main thread for calling the other nodes.
class MeshThread implements Runnable {
org.omg.CORBA.BOA boa;
public MeshThread(org.omg.CORBA.BOA boa) {
this.boa = boa;
}
public void run() {
boa.impl_is_ready(null);
}
}
|
Figure 5-4. MeshThread.java
In each node we incarnate a new object, activate it and announce the object reference to the server. Then we wait for the other nodes to complete the same. After that, each node retrieves the references to all other nodes from the server. The clients synchronize again and then start calling each others objects in turn.
...
// register an RTT
RTT_impl rtt = new RTT_impl();
factory.registerRTT(id, rtt);
Thread srv = new Thread(new MeshThread(boa));
srv.start();
Barrier b = factory.getBarrier();
b.barrier(clients); // wait for others
// get references to the other RTTs
RTT[] otherRTTs = new RTT[clients-1];
{
int j = 0;
for(int i = 0; i<clients; i++) {
if (i != id) {
otherRTTs[j] = factory.lookupRTT(i);
j++;
}
}
}
long t1 = 0;
long t2 = 0;
if (method.equals("sync_VV")) {
b.barrier(clients); // wait for others
t1 = System.currentTimeMillis();
for (int i=0; i<loops; i++) {
for (int j=0; j<otherRTTs.length; j++) {
otherRTTs[j].sync_VV();
}
}
t2 = System.currentTimeMillis();
}
...
System.out.println(t2-t1);
|
Figure 5-5. MeshClient.java
Results
As for the star architecture, we distinguish between completion time and (accumulated) round trip time. The former is the wall clock time needed to process all calls, the latter is the sum of every client's round trip time.
There are a total of 1000 calls in the mesh, no matter how many clients (actually, we may have more but scale back to 1000 calls, as the number of calls is not always evenly divisable).
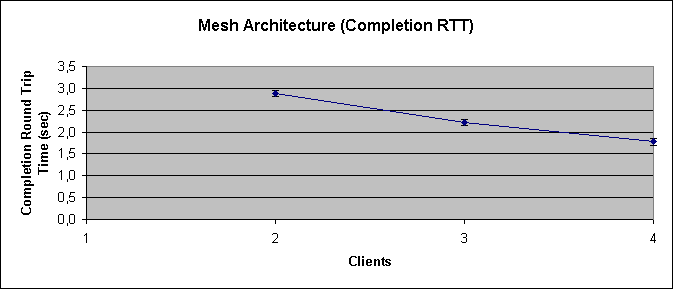
In Figure 5-6, we see the completion round trip time falling. Ideally it would fall with a rate of 1/n, with n nodes in the mesh. With busy nodes and some requests colliding, i.e. two nodes call the same node, this is not achievable.
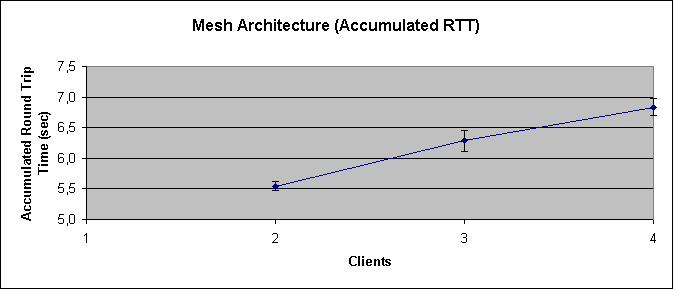
Figure 5-7 shows an increase in the (accumulated) round trip time. Ideally, it should stay the same, as each node takes its share of the total calls and processes it. I.e., the total processing cost should be the same. But again, busy nodes and colliding requests prevent this.